
Valgrind 介绍
Valgrind包含多个工具,如Memcheck,Cachegrind,Helgrind, Callgrind,Massif,尤其擅长处理内存泄漏问题和非法内存访问的问题。 Valgrind工具可以有效的帮助你分析出问题的产生的原因。
下面分别介绍个工具的作用:
Memcheck 工具主要检查下面的程序错误:
- 使用未初始化的内存 (Use of uninitialised memory)
- 使用已经释放了的内存 (Reading/writing memory after it has been free’d)
- 使用超过 malloc分配的内存空间(Reading/writing off the end of malloc’d blocks)
- 对堆栈的非法访问 (Reading/writing inappropriate areas on the stack)
- 申请的空间是否有释放 (Memory leaks – where pointers to malloc’d blocks are lost forever)
- malloc/free/new/delete申请和释放内存的匹配(Mismatched use of malloc/new/new [] vs free/delete/delete [])
- src和dst的重叠(Overlapping src and dst pointers in memcpy() and related functions)
Callgrind
Callgrind收集程序运行时的一些数据,函数调用关系等信息,还可以有选择地进行cache模拟。在运行结束时,它会把分析数据写入一个文件。callgrind_annotate可以把这个文件的内容转化成可读的形式。
Cachegrind
它模拟 CPU中的一级缓存I1,D1和L2二级缓存,能够精确地指出程序中 cache的丢失和命中。如果需要,它还能够为我们提供cache丢失次数,内存引用次数,以及每行代码,每个函数,每个模块,整个程序产生的指令数。这对优化程序有很大的帮助。
Helgrind
它主要用来检查多线程程序中出现的竞争问题。Helgrind寻找内存中被多个线程访问,而又没有一贯加锁的区域,这些区域往往是线程之间失去同步的地方,而且会导致难以发掘的错误。Helgrind实现了名为” Eraser” 的竞争检测算法,并做了进一步改进,减少了报告错误的次数。
Massif
堆栈分析器,它能测量程序在堆栈中使用了多少内存,告诉我们堆块,堆管理块和栈的大小。
Massif能帮助我们减少内存的使用,在带有虚拟内存的现代系统中,它还能够加速我们程序的运行,减少程序停留在交换区中的几率。
Valgrind使用非常简单,你只需要在原本需要执行的可执行程序的前面加上Valgrind就可以。
./a.out
valgrind ./a.out
12假设你的代码没有任何内存的问题或者内存泄漏, Valgrind将打印出类似于下面的内容。如果你的代码存在一些问题,将会在下面的输出中增加一些问题的输出。

上面的输出的内容中,最重要的便是HEAP SUMMARY和 ERROR SUMMARY 。
如果你的程序没有任何问题,在HEAP SUMMARY你就会看见 in use at exit: 0 bytes in 0 blocks。在 ERROR SUMMARY , 你就会看见0 errors from 0 contexts (suppressed: 0 from 0)。
Valgrind 代码故障排查
需要在下面的场景下使用Valgrind:
- 你的程序在运行时发生了未定义的行为,例如运行程序多次,得到的结果每次都不相同,且不是符合预期的。
- 你的程序产生了段错误。
- 运行 C 可执行文件后,您会看到诡异的内存输出。
- 你的程序不允许有memory leak或者非法访问。
在工作中,应该尽可能的使用Valgrind对代码进行检查,因为人人都有可能犯一些低级错误。
修复内存泄漏
#include <stdlib.h>
int *f1() {
int *ip = malloc(sizeof(int));
*ip = 3;
return ip;
}
int f2() {
int *internal = f1();
return *internal;
}
int main() {
int i = f2();
return i;
}
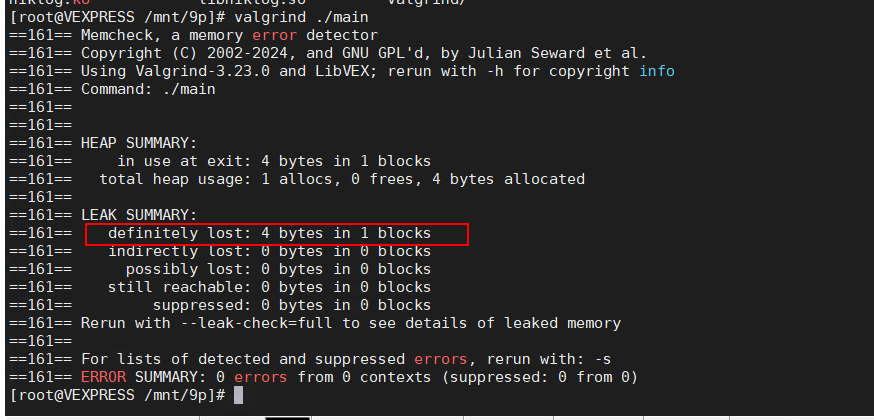
编译上面的程序使用Valgrind运行,你会获得下面的输出。
解释一下内存泄漏类型:
definitely lost:指确定泄露的内存,应尽快修复。当程序结束时如果一块动态分配的内存没有被释放且通过程序内的指针变量均无法访问这块内存则会报这个错误。
indirectly lost:指间接泄露的内存,其总是与 definitely lost 一起出现,只要修复 definitely lost 即可恢复。当使用了含有指针成员的类或结构时可能会报这个错误
possibly lost:指可能泄露的内存,大多数情况下应视为与 definitely lost 一样需要尽快修复。当程序结束时如果一块动态分配的内存没有被释放且通过程序内的指针变量均无法访问这块内存的起始地址,但可以访问其中的某一部分数据,则会报这个错误。
still reachable:如果程序是正常结束的,那么它可能不会造成程序崩溃,但长时间运行有可能耗尽系统资源,因此笔者建议修复它。如果程序是崩溃(如访问非法的地址而崩溃)而非正常结束的,则应当暂时忽略它,先修复导致程序崩溃的错误,然后重新检测。
suppressed:已被解决。出现了内存泄露但系统自动处理了。可以无视这类错误。
从上面的输出中,可以非常明显的看出我们产生了一个内存泄漏。我们产生了4个byte的内存泄漏,因为我们使用malloc申请了一个int大小的内存,但是之后指向该内存的指针丢失了,产生了泄漏。 按照输出中最后一行的建议
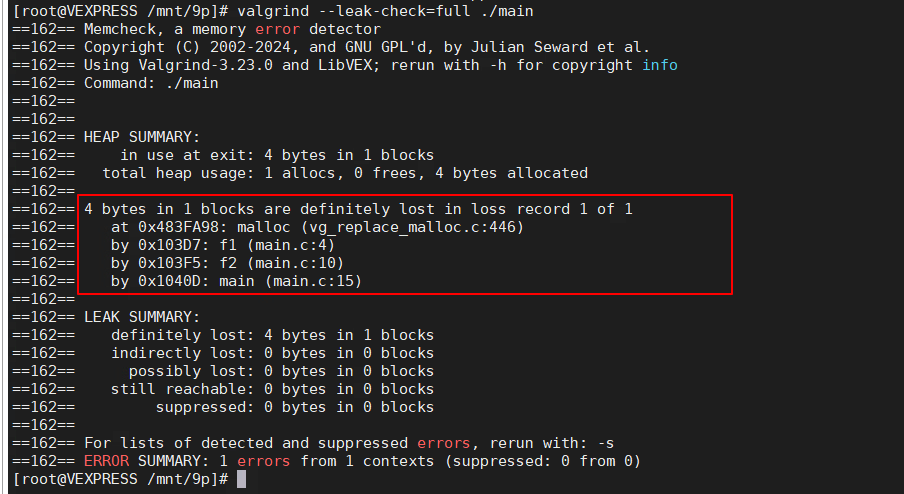
valgrind --leak-check=full ./main
你可以获取更加详细的堆栈。
修复非法内存访问
#include <stdlib.h>
int *f1() {
int *ip = malloc(sizeof(int));
*ip = 3;
return ip;
}
int f2() {
int *internal = f1();
int left = internal[0];
int right = internal[2];
free(internal);
return left + right / 2;
}
int main() {
int i = f2();
return i;
}
编译运行上面的代码,使用Valgrind运行,将会得到下面的输出。
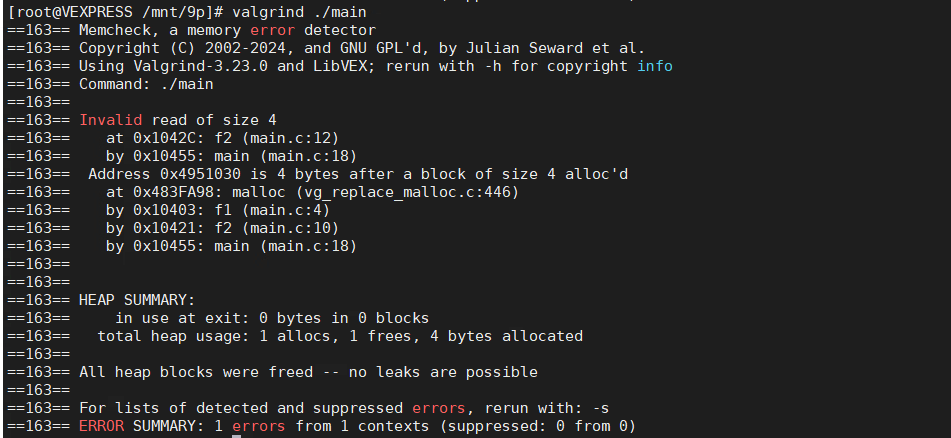
可以看出 错误信息中分别告诉了我们在哪里访问的异常内存,以及额外告诉我们要读取的位置在我们申请的内存块的末尾处后面的4个字节。这意味着我们正在读取的位置超过了我们申请的内存的大小。
修复非法free
#include <stdlib.h>
int *f1() {
int *ip = malloc(sizeof(int));
*ip = 3;
return ip;
}
int f2() {
int *internal = f1();
void *other = (void*)internal;
int result = *internal;
int *result2 = &result;
free(internal);
free(other);
free(result2);
return result;
}
int main() {
int i = f2();
return i;
}
编译运行上面的代码,使用Valgrind运行,将会得到下面的输出
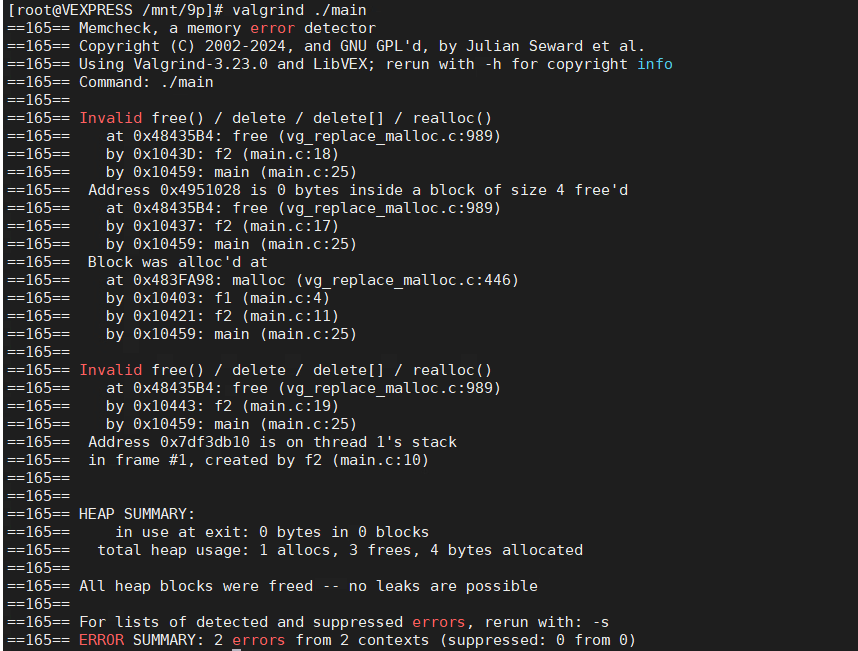
第一个error告诉我们第18行的调用是非法的。其详细的信息是”0 bytes inside a block of size 4 free’d”。说的直白一点,这句话的含义是我们尝试free同一个指针两次。
什么时候进行的第一次free,在下面的输出中也可以轻易的找到。可以看到第一次free的位置在程序的第17行。
与此同时,被free两次的内存所申请的位置也给了出来, 在第4行 int *ip = malloc(sizeof(int));申请。
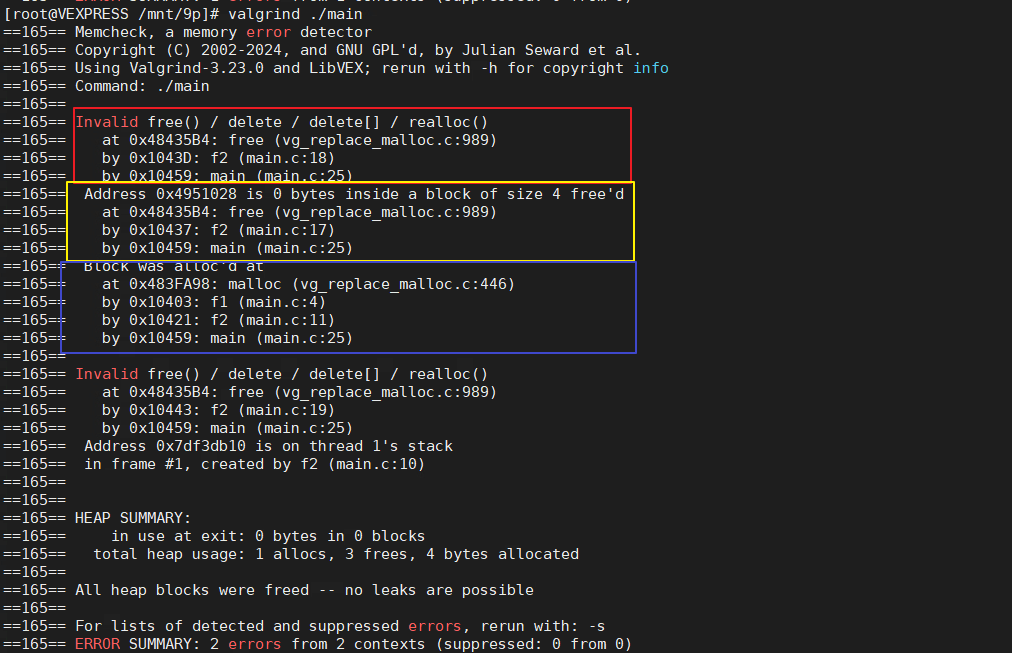
上面的输出的第二部分还指出,程序还存在另一处free的错误,在程序的19行。我们尝试进行free的内存位于栈上。换句话说,我们尝试去free一个指向本地变量的指针。
修复未初始化
#include <stdlib.h>
int *f1() {
int *ip = malloc(sizeof(int));
return ip;
}
int f2() {
int *internal = f1();
int other = 3;
if(*internal < 5) {
other = *internal;
}
free(internal);
return other;
}
int main() {
int i = f2();
return i;
}
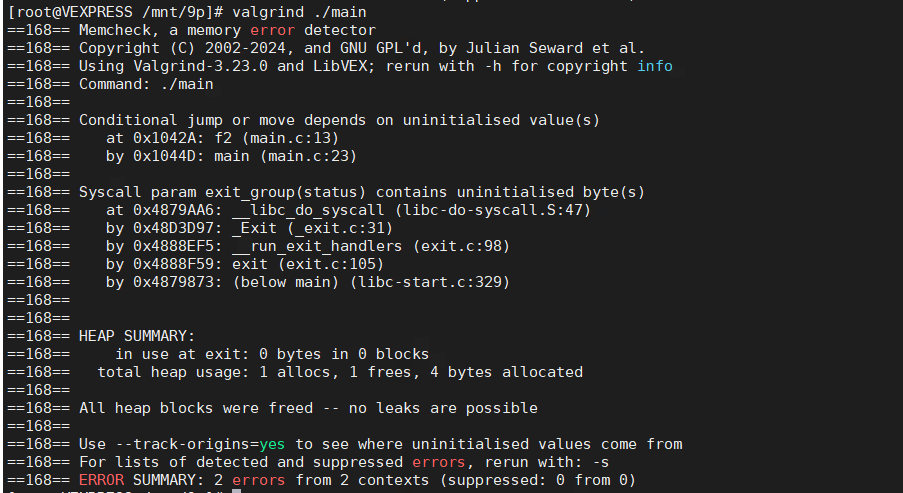
上面的输出告诉我们的第一处错误是我们的代码根据一个没有被初始化的值进行条件跳转或转移,条件跳转或转移通常是值if语句或者while循环。该错误发生在第13行。我们看到使用了if语句进行判断 if(*internal < 5)。可以看出这里这里问题在于在函数外尝试访问已调用完成的函数的栈上的地址。
Valgrind 代码性能调优
Valgrind除了支持进行内存检查,还支持C的代码profiling,提供cachegrind和 callgrind 。cachegrind主要是统计CPUL1/L2cache的命中数;而callgrind统计函数调用次数以及CPU指令执行次数。C语言本身提供了类似的gprof功能,但是gprof的实现需要编译器支持,但是很多交叉编译器对该功能的支持非常弱,而且只支持单线程。valgrind是很好的替代方案。
valgrind –tool=callgrind –callgrind-out-file=callgrind.log your-program [program options]
如果是多线程程序需要添加–separate-threads=yes
使用该命令运行程序 结束后会生成 callgrind.log
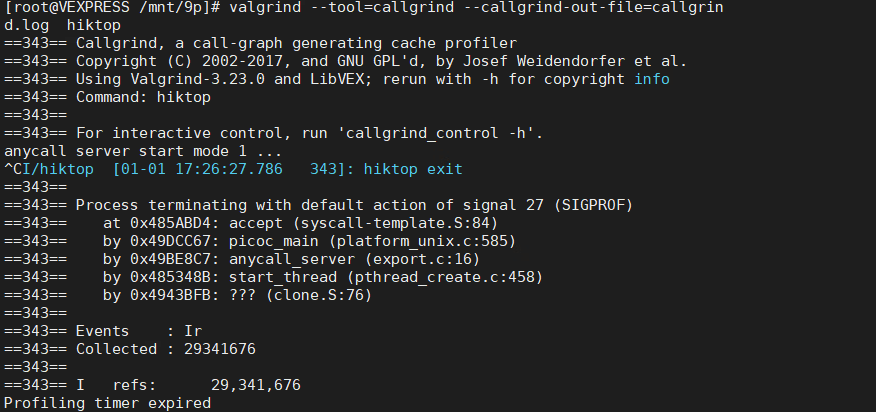
Ir的意思是 instruction read , collected是说明已经收集了2931676次
理解Ir次数
Ir次数可以简单理解为CPU指令执行的次数。一句C写的普通代码,一般可以转为一两句或者若干句指令。所以它统计的可能不是代码层级的。
我们还需要使用专用工具查看这个调用信息。可用的一般是kcachegrind:
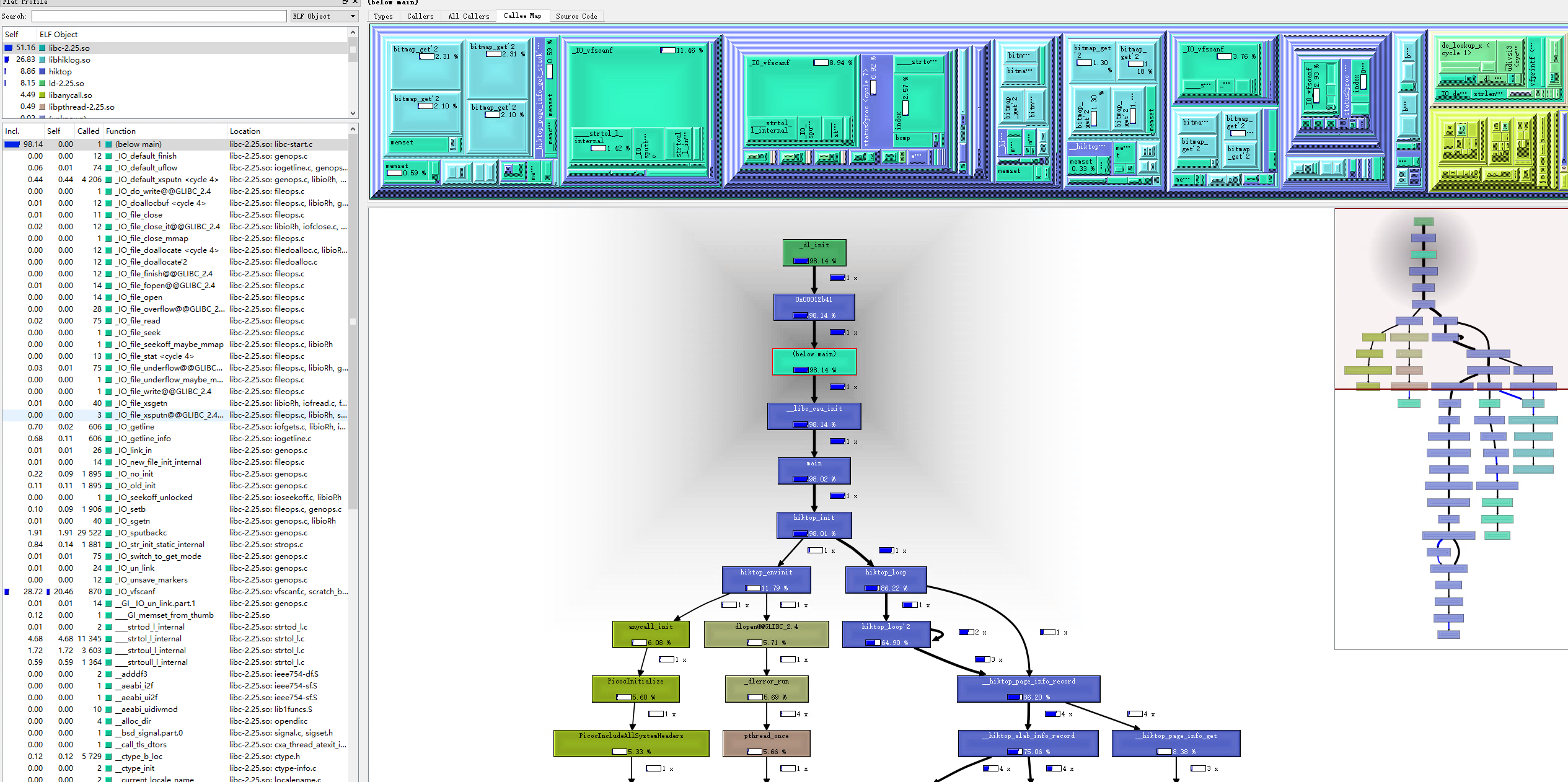
可以看出valgrind帮我们统计出了所有函数的调用过程,以及调用次数,CPU占用等信息,该信息可以非常方便的让我们找到函数调用中的性能短板,对我们进行性能优化是非常有用的。
Valgrind性能调优示例
我们看一下Valgrind进行性能优化的实例:
int main()
{
int i =0;
int id;
pthread_t thread[2];
for(i =0 ;i< 2; i++)
{
id = pthread_create(&thread[i], NULL, fun, NULL);
printf("thread =%d n",i);
}
for(i =0 ;i< 2; i++)
{
pthread_join(thread[i] , NULL);
}
return 0;
}
void* fun(void * argv)
{
clock_t start, end;
double cpu_time_used;
start = clock();
fun2();
end = clock();
cpu_time_used = ((double) (end - start)) / CLOCKS_PER_SEC;
printf("TIME: %f s n", cpu_time_used);
return NULL;
}
void fun2()
{
int n = 0;
while (n < 1024 * 8) {
char buf[1024 * 8] = {0};
sprintf(buf, "%lun", n++);
printf(buf);
}
}这是原始代码,代码非常简单就是创建了两个线程,两个线程进行循环打印。用valgrind运行这个程序。
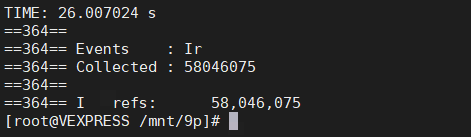
用时26S。
然后我们打开分析程序。
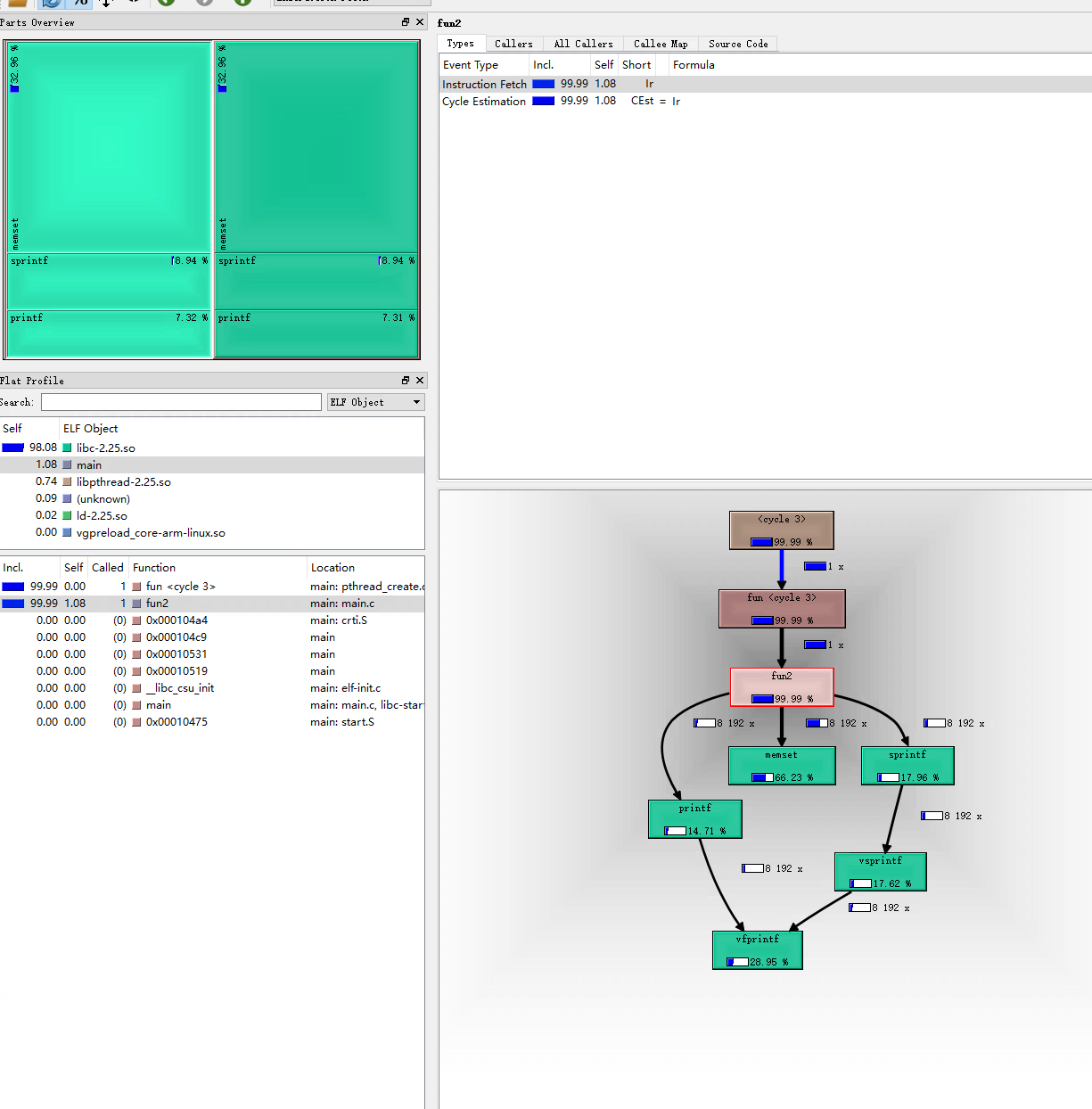
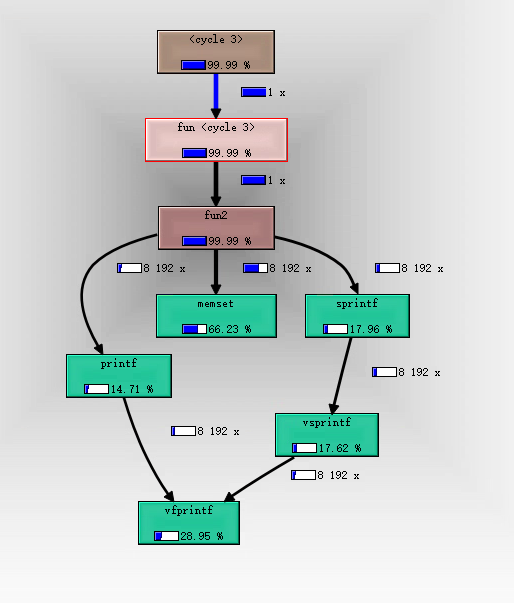
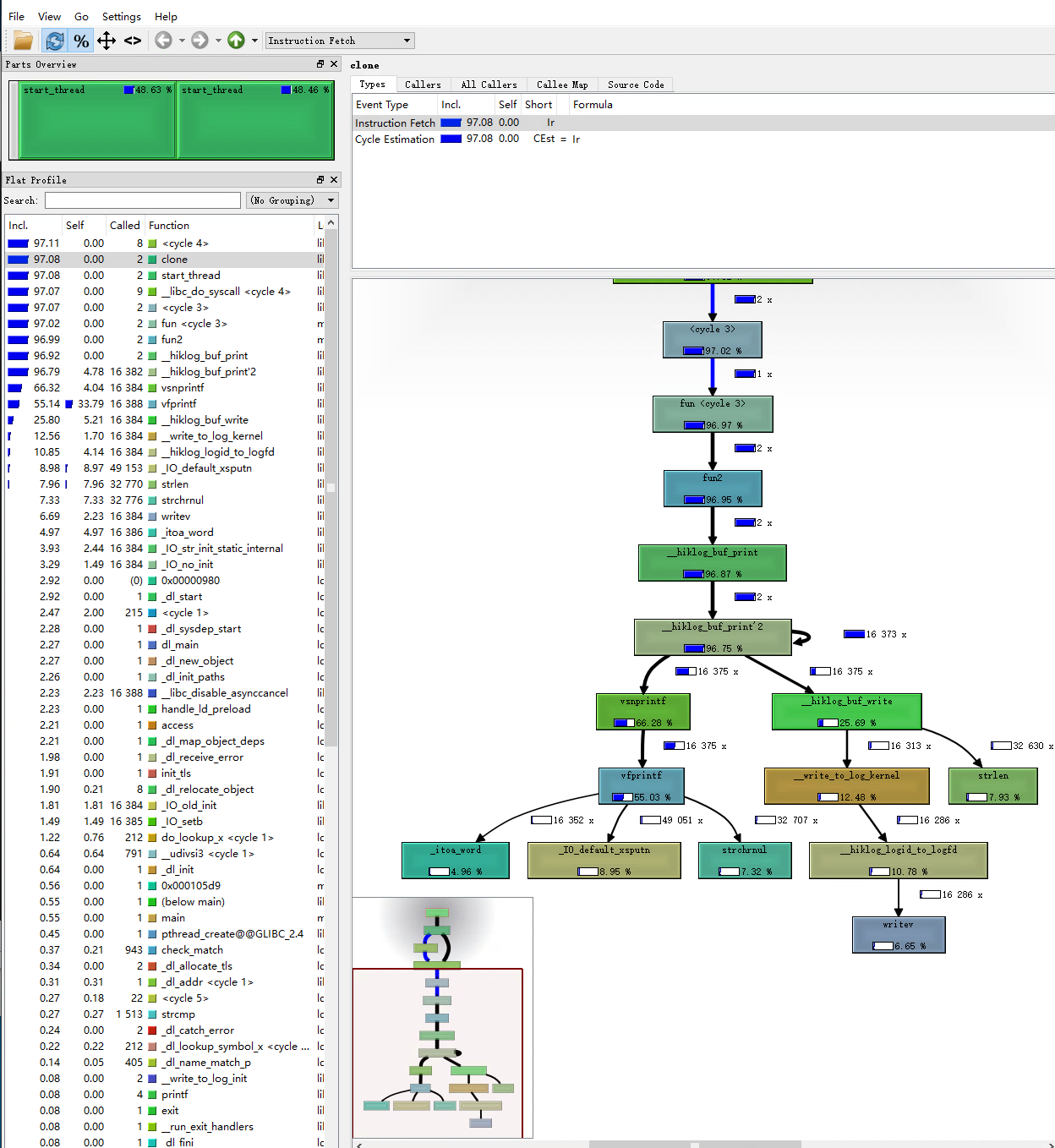
我们点击线程信息区域的t1,再在线程内函数信息区域点击func2,调用关系图区域显示。
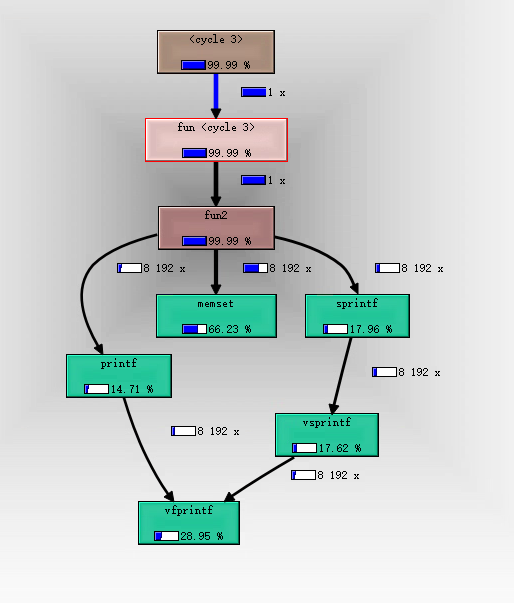
但是我们可以看到每个函数内部的CPU资源占用——函数框内部的百分比数值,和每个函数的调用次数——线条旁的数字。这些信息也可以在线程内函数信息区域看到。
有了CPU资源占用占比和调用次数等信息,我们就可以分析性能瓶颈了。虽然在valgrind中运行的程序比正常运行的都要慢很多,但是这种慢可以认为是对所有操作都慢,所以我们只要查看某个过程在整体中的占比就可以了。
上图我们看到,memset几乎占用的所有的CPU资源。可是我们代码中没有memset啊!
虽然我们代码中没有显示调用memset,但是在使用0初始化数组时,编译器是使用memset实现的。
那么我们不初始化数组,代码改成void fun2()
{
int n = 0;
while (n < 1024 * 8) {
char buf[1024 * 8];
sprintf(buf, "%lun", n++);
printf(buf);
}
}修改后调用结果变成如下,修改后用时21s:
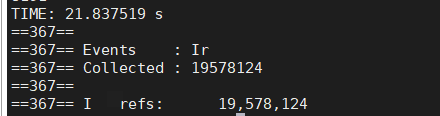
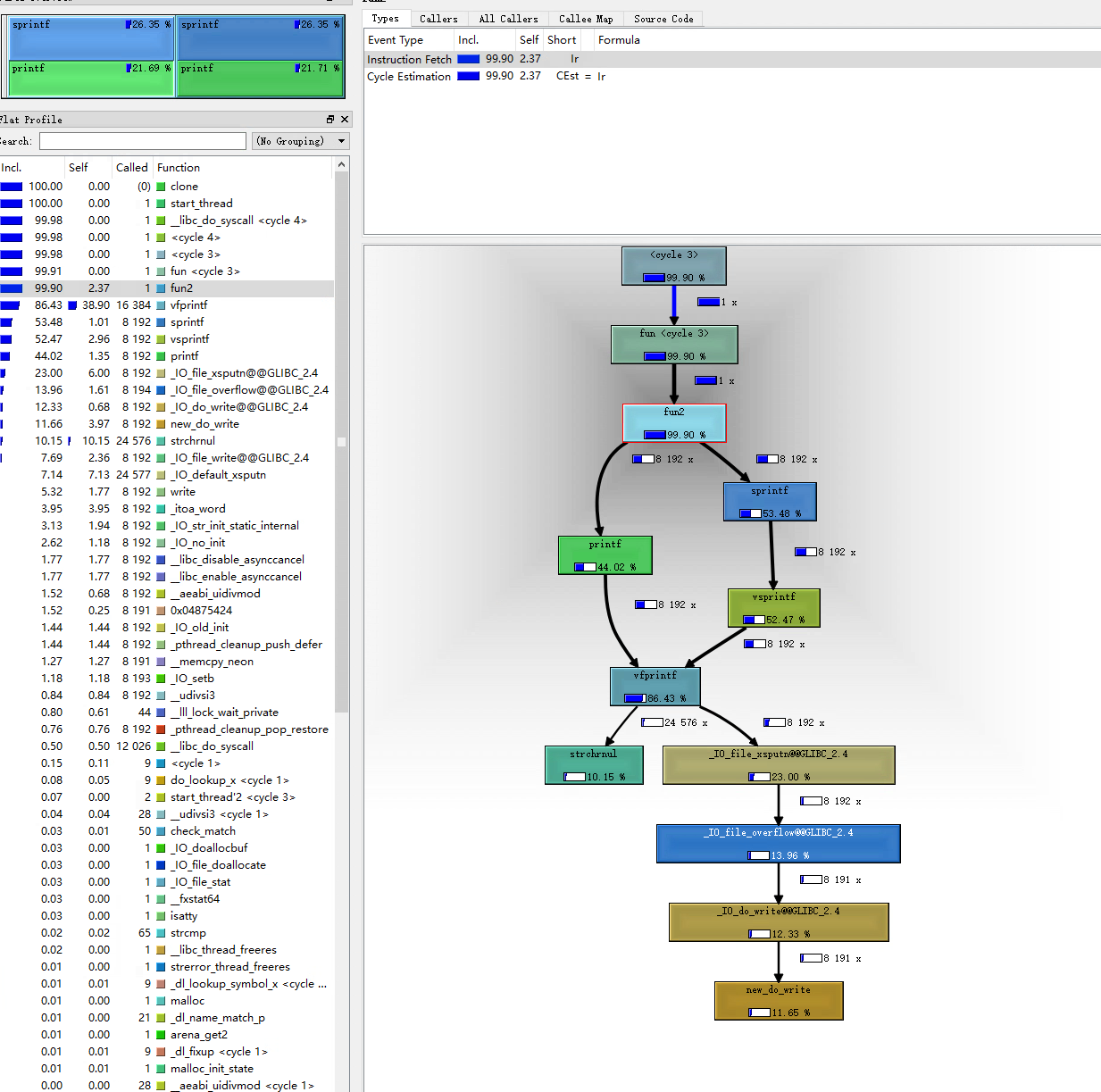
这个时候我们发现性能瓶颈来到了vfprintf,printf(包括自身和其调用的vfprintf)资源占比只有44.02%,而sprintf资源占比则有52.47%。那么如果我们优化掉sprintf,则调用效率应该又会有所提升。
void fun2()
{
int n = 0;
while (n < 1024 * 8) {
printf("%lun", n++ );
}
}可是优化结果并不理想: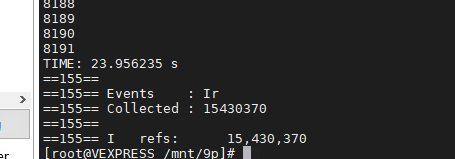
这并不符合我们的分析,那什么原因呢?
串口也是一种资源,我们在串口上输出信息也是占用一种资源,而且这种资源是稀缺的。所以说实际上目前的瓶颈在于printf最耗时。我们使用最近开发的打印接口,将结果输入环形缓冲区试一试:
void fun2()
{
int n = 0;
while (n < 1024 * 8) {
hiklog_system_info("%lun", n++ );
}
}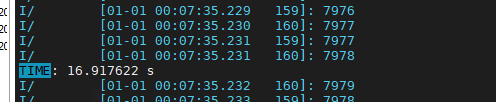
可以看到效果不错。在有读者的情况下需要16S,没有读者的情况只需要14s。
注意事项
- 待测试程序编译过程是否使用-O 可能会影响valgrind的检测结果
- valgrind只能检测运行代码的性能,如果程序执行过程中部分代码没有执行,那么这部分肯定是检测不到的
- valgrind只是做Ir 计数,所以理论上它不是对时间的统计。只能从指令层反应时间的可能消耗
Valgrind 原理
Memcheck 能够检测出内存问题,关键在于其建立了两个全局表。
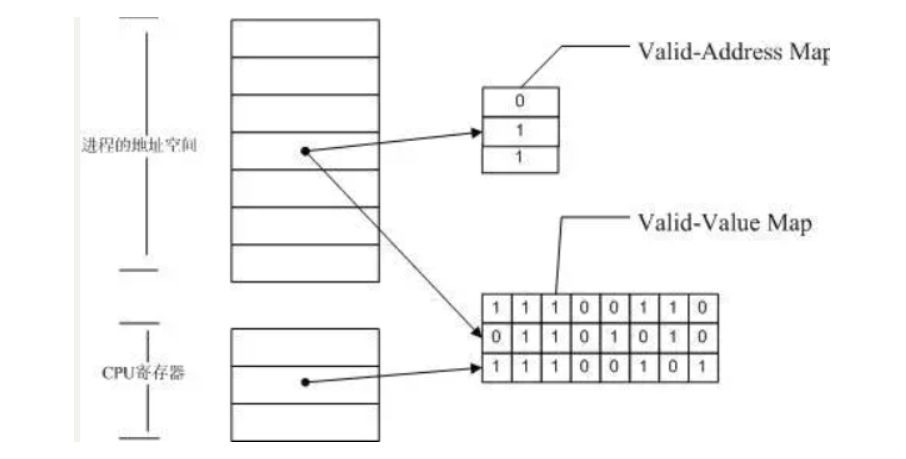
- Valid-Value 表:
对于进程的整个地址空间中的每一个字节(byte),都有与之对应的 8 个 bits;对于 CPU 的每个寄存器,也有一个与之对应的 bit 向量。这些 bits 负责记录该字节或者寄存器值是否具有有效的、已初始化的值。
- Valid-Address 表
对于进程整个地址空间中的每一个字节(byte),还有与之对应的 1 个 bit,负责记录该地址是否能够被读写。
检测原理:
- 当要读写内存中某个字节时,首先检查这个字节对应的 A bit。如果该A bit显示该位置是无效位置,memcheck 则报告读写错误。
- 内核(core)类似于一个虚拟的 CPU 环境,这样当内存中的某个字节被加载到真实的 CPU 中时,该字节对应的 V bit 也被加载到虚拟的 CPU 环境中。一旦寄存器中的值,被用来产生内存地址,或者该值能够影响程序输出,则 memcheck 会检查对应的V bits,如果该值尚未初始化,则会报告使用未初始化内存错误。
在资源消耗方面,由于Valgrind 采用虚拟处理器方式运行应用程序,并且使用了V-bit 对每一位数据进行控制,因此使用Valgrind 调试程序时会大量占用内存,并且程序的运行速度要比在实际处理器上运行时的速度慢20 到30 倍。
留言