

Linux Pstore
内核本身支持使用保留内存进行一些崩溃日志存储。可以了解一下这种机制:
pstore最初是用于系统发生oops或panic时,自动保存内核log buffer中的日志。不过在当前内核版本中,其已经支持了更多的功能,如保存console日志、ftrace消息和用户空间日志。同时,它还支持将这些消息保存在不同的存储设备中,如内存、块设备或mtd设备。 为了提高灵活性和可扩展性,pstore将以上功能分别抽象为前端和后端,其中像dmesg、console等为pstore提供数据的模块称为前端,而内存设备、块设备等用于存储数据的模块称为后端,pstore core则分别为它们提供相关的注册接口。
通过模块化的设计,实现了前端和后端的解耦,因此若某些模块需要利用pstore保存信息,就可以方便地向pstore添加新的前端。而若需要将pstore数据保存到新的存储设备上,也可以通过向其添加后端设备的方式完成。

除此之外,pstore还设计了一套pstore文件系统,用于查询和操作上一次重启时已经保存的pstore数据。当该文件系统被挂载时,保存在backend中的数据将被读取到pstore fs中,并以文件的形式显示。
pstore使用方法
ramoops
配置内核
CONFIG_PSTORE=y
CONFIG_PSTORE_CONSOLE=y
CONFIG_PSTORE_PMSG=y
CONFIG_PSTORE_RAM=y
CONFIG_PANIC_TIMEOUT=-1由于log数据存放于DDR,不能掉电,只能依靠自动重启机制来查看,故而要配置: CONFIG_PANIC_TIMEOUT ,让系统在 panic 后能自动重启。
dts
ramoops_mem: ramoops_mem {
reg = <0x0 0x110000 0x0 0xf0000>;
reg-names = "ramoops_mem";
};
ramoops {
compatible = "ramoops";
record-size = <0x0 0x20000>;
console-size = <0x0 0x80000>;
ftrace-size = <0x0 0x00000>;
pmsg-size = <0x0 0x50000>;
memory-region = <&ramoops_mem>;
};pstore fs
挂载pstore文件系统
mount -t pstore pstore /sys/fs/pstore挂载后,通过 mount能看到类似这样的信息:
# mount
pstore on /sys/fs/pstore type pstore (rw,relatime)如果需要验证,可以这样主动触发内核崩溃:
# echo c > /proc/sysrq-trigger不同配置方式日志名称不同
ramoops
# mount -t pstore pstore /sys/fs/pstore/
# cd /sys/fs/pstore/
# ls
console-ramoops-0 dmesg-ramoops-0 dmesg-ramoops-1pmsg
较新的内核版本还支持在用户态输出日志到pstore
HikRamfs
pstore的体系非常完善,是一种非常合适的崩溃信息保存手段,还支持ECC对于数据的纠错功能。但是这种方式也有问题,pstore的文件系统非常死板,不支持用户日志保存,只能通过内核自带的几个前端接口进行日志保存,我们需要基于pstore的基本原理实现一个新的文件系统,该文件系统可以挂载在Linux的保留内存中可以和正常的文件系统一样存储任意文件支持文件夹。
框架设计
hikramfs 主要功能就是将1-4M的物理内存组织成一个可读可写的文件系统,并且该文件系统可以在系统重启,Panic,oom等异常事件触发后保存现场信息到到这个文件系统中。
下面是hikramfs组织内存块使用到的主要数据结构:
// 最多承载 1024*4096=0x400000 4M 内存空间
// 定义每一个目录项的格式
typedef struct hikramfs_dir_entry {
char filename[HIKRAMFS_MAX_FILELEN];
uint16_t idx;//索引文件块
}hikramfs_dir_entry_t;
typedef enum hikramfs_blk_type{
HIKRAMFS_BLK_FILEDATA = 1,//数据块
HIKRAMFS_BLK_FILEREG = 2,//文件块
HIKRAMFS_BLK_FILEDIR = 3 //目录块
}hikramfs_blk_type_e;
typedef struct hikramfs_super_blk{
uint32_t magic;//0xafafafaf 文件系统标记
uint32_t times;//记录挂载次数
uint32_t bitmap[HIKRAMFS_MAXBLOCK_NUMS/32]; //标记blk使用情况
}hikramfs_super_blk_t;
typedef struct hikramfs_data_blk {
uint8_t busy; //文件被使用
uint8_t mode; //数据块类型
uint16_t idx; //索引关联文件块
uint16_t blknums;//已经占用多少文件块
union{
uint32_t file_size;//文件块作为文件长度
uint32_t file_nums;//目录块记录文件数目
};
uint8_t data[HIKRAMFS_BLOCKDATASIZE];//数据
uint32_t crc;//校验值
}hikramfs_data_blk_t;
在内存中这样组织:

superblock 存在在保留内存最开始的地方,然后之后所有的内存全部划分为datablock。datablock有三种类型分别代表数据块 ,文件块,目录块。
其中第一个datablock永远是目录块代表这个文件系统的根目录。
如此在根目录中存放一个文件的情况大致如下

这个文件目前占用四个数据块,存放16K的数据。
[root@MTK7986 /mnt/hikramfs]# anycall -e "k hikramfs_dump"
[78445.789488] kcall_write:hikramfs_dump
[78445.795116] func have 0 arg.
[78445.797996] TIMES : 2
[78445.800341] TOTAL : 254
[78445.802862] USED : 5
[78445.805206] SIZE : 1048576
[78445.808074] PHY ADDR: 0x42f00000
[78445.811374] VIRT ADDR: 0x12300000
[78445.814761] DATA ADDR: 0x12300088
[78445.818149] NODE 0 MODE 3 USED 1 FILE_INFO 1 LINK 0 BLKNUMS 0 CRC b281c999
[78445.818152] DIR CONTAINS hello @1
[78445.825094] NODE 1 MODE 2 USED 1 FILE_INFO 12288 LINK 2 BLKNUMS 3 CRC 718d1963
[78445.828568] FILE BLOCK:
[78445.835864] DATA:0000000021d24ebe: 2f d2 b4 ac 9b ab ba 11 5f cf 5e 9d 8a f7 05 5f /......._.^...._
[78445.847754] DATA:0000000039c0368e: 33 34 37 44 fa 5a d9 2f 347D.Z./
[78445.856428] FILE CONTAINS BLK:
[78445.856431] 2 3 4
[78445.859474] NODE 2 MODE 1 USED 1 FILE_INFO 0 LINK 3 BLKNUMS 0 CRC 438e49fd
[78445.861470] DATA BLOCK:
[78445.868415] DATA:000000009a5d170c: ea 5f 27 65 d0 7b e3 44 13 ef 15 3b c4 71 d4 f1 ._'e.{.D...;.q..
[78445.880303] DATA:000000007bc32c5f: 3b 39 0e 6b ab 66 d0 21 ;9.k.f.!
[78445.888978] NODE 3 MODE 1 USED 1 FILE_INFO 0 LINK 4 BLKNUMS 0 CRC f89eccb3
[78445.888979] DATA BLOCK:
[78445.895923] DATA:000000005d4f2fdb: 75 59 5b da 9b f6 88 f6 5e dc d9 75 04 6b 56 2c uY[.....^..u.kV,
[78445.907812] DATA:00000000a21d366d: d1 82 a5 a9 e3 e5 9d 0b ........
[78445.916486] NODE 4 MODE 0 USED 1 FILE_INFO 0 LINK 0 BLKNUMS 0 CRC 31ed7efa
[78445.916487] NOUSE BLOCK:
[78445.923432] DATA:00000000b86d894a: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
[78445.935407] DATA:000000000e95f6a2: 00 00 00 00 00 00 00 00 ........
[78445.944120] kcall return:0000000000000000然后再复杂一点,再创建一个文件后再扩大之前的文件会这么样呢:

大致情况会变成这样。
如此大概可以看出这个文件系统的基本组织方式,目录块中会存放dir_entry,这个dir_entry可以指向文件块也可以指向目录块,这就可以决定一个目录下有多少文件和目录,然后就是文件块和目录块,文件块其实也是一种数据块,用来标记文件的开头位置。然后每一个文件的数据块会通过idx,关联到下一个文件块。通过这种方式就可以组织出一个基本的文件系统结构。
重启以及Panic原因记录功能
hikramfs 还通过在系统重启以及Panic等代码中注册notify链,可以保存重要现场信息。
echo c > /proc/sysrq-trigger 触发panic,系统重启后存在这两个文件:
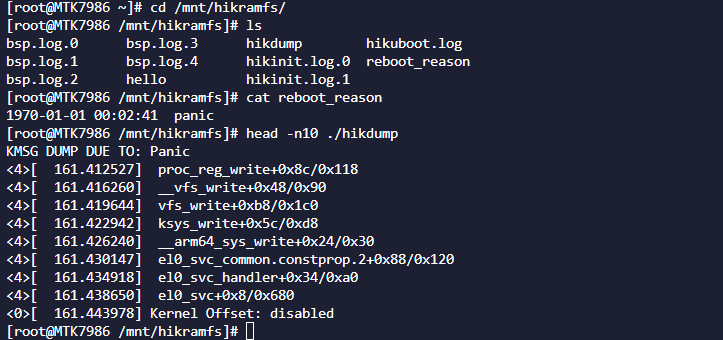
reboot_reason 记录重新时间以及重启原因。
hikdump记录了panic前的内存打印。
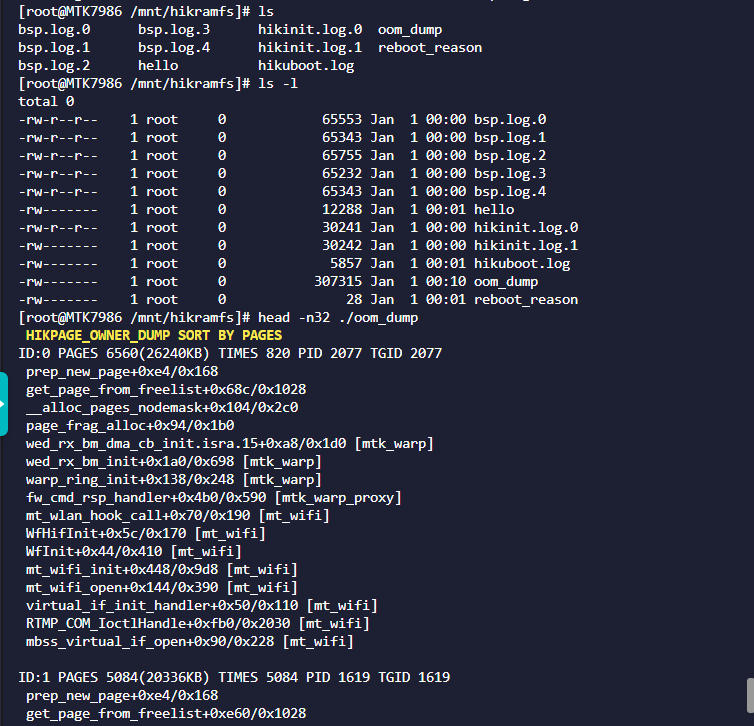
OOM原因记录
echo f > /proc/sysrq-trigger
oom_dump中存放着触发oom后的内存现场信息。
Linux适配方法
Linux适配该文件系统其实难点在于创建保留内存,这一点和pstore是一样的,上层软件基本不需要关心只需要使用即可。创建预留内存的方法之后再说,先看这么适配hikramfs。内核态适配除了预留内存的创建,只需要添加启动参数即可。

然后需要在根文件系统的启动脚本中挂载,挂载命令如下:
mount -t hikramfs nodev /mnt/hikramfs -o paddr=0x42f00000,size=0x100000
这里的两个数据可以cmdline中取出。
uboot适配方法
hikramfs最底层的代码是跨平台的,可以直接移植到uboot中使用。
在uboot的board_init_r中添加下面的函数:
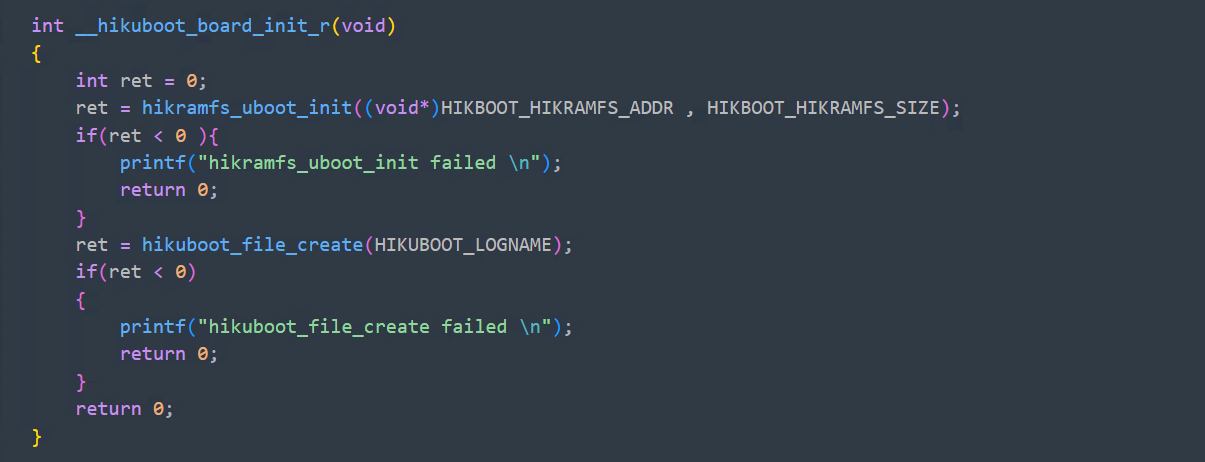
第一个函数的作用就是初始化hikramfs数据,第二个是创建一个uboot日志文件。
然后需要修改uboot puts 函数代码。
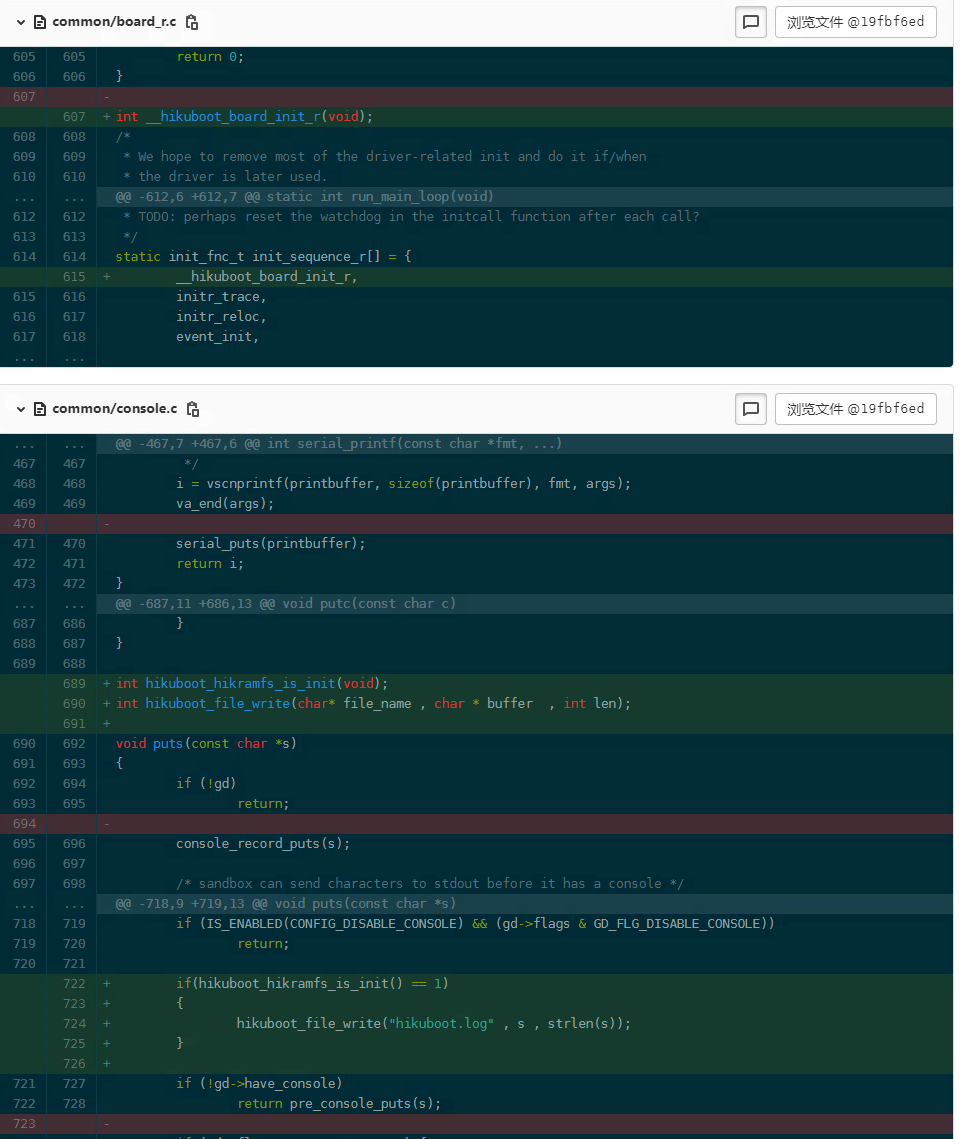
通过这样的修改可以将uboot的日志保存到hikramfs中可以在系统启动后查看uboot的打印信息。
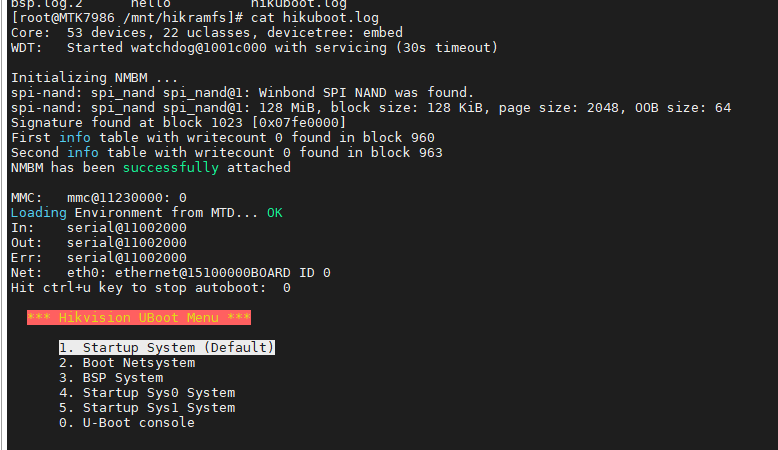
此外在Uboot中还可以通过命令行操作hikramfs中的文件。
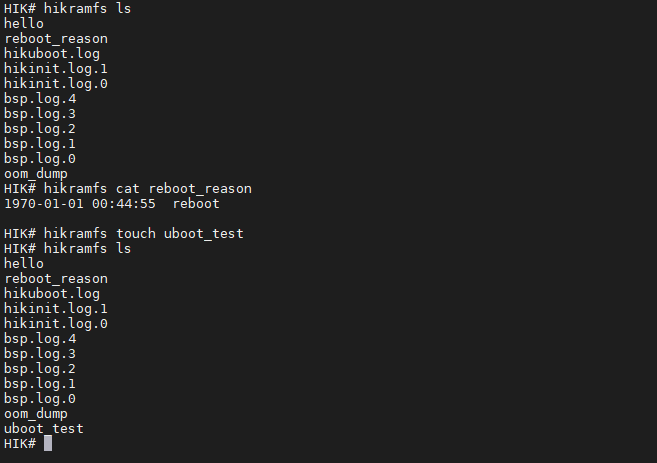
Linux内存预留手段与访问方法
无论是pstore还是hikramfs,其实适配的真正难点在于创建预留内存,日常开发过程可能要预留一段物理内存出来提供特殊场景使用(独占一段内存不被系统所使用)。本节讲述两种可以创建保留内存的方法以及使用预留内存的方法。
内核启动参数mem
该方法的核心就是通过限制linux和uboot可以感知到的总内存从系统的最后扣出一块内存。
以vexpress平台为例,首先需要限制linux和uboot可以感知到的内存。
linux可以通过mem传参限制住内存数量 ,总内存256M的情况下可以传参:
mem=255M保留住1M内存。
uboot需要修改dram_init代码,限制内存大小:
int dram_init(void)
{
gd->ram_size =
get_ram_size((long *)CONFIG_SYS_SDRAM_BASE, PHYS_SDRAM_1_SIZE);
gd->ram_size -= 0x100000;
return 0;
}
int dram_init_banksize(void)
{
gd->bd->bi_dram[0].start = PHYS_SDRAM_1;
gd->bd->bi_dram[0].size =
get_ram_size((long *)PHYS_SDRAM_1, PHYS_SDRAM_1_SIZE);
gd->bd->bi_dram[0].size -= 0x100000;
gd->bd->bi_dram[1].start = PHYS_SDRAM_2;
gd->bd->bi_dram[1].size =
get_ram_size((long *)PHYS_SDRAM_2, PHYS_SDRAM_2_SIZE);
return 0;
}这种方式的内存分布如下:

这种方式的优点是通用性好,不会造成物理内存空洞,缺点是需要修改uboot dram_init代码,这部分代码修改风险较高容易造成调试时设备变砖,还有就是内存大小如果变化会直接导致你想要预留内存的地址变化,不同内存大小的平台需要单独兼容。
memblock内存预留
memblock介绍
Linux内核使用伙伴系统管理内存,那么在伙伴系统之前,比如自举阶段,内核是如何管理内存的呢?答案是通过memblock来管理,它是bootmem 的后续者。原先它叫做 Logical Memory Block, 之后内核接纳了 Yinghai Lu 提供的补丁后改名为 memblock。在系统启动阶段,使用memblock记录物理内存的使用情况。
memblock数据结构
首先我们知道在内核启动后,对于内存,分成好几块:
- 内存中的某些部分使永久分配给内核的,例如代码段和数据段,ramdisk和dtb占用的空间等,是系统内存的一部分,不能被侵占,也不参与内存的分配,称之为静态内存;
- GPU/camera/多核共享的内存都需要预留大量连续内存,这部分内存平时不使用,但是必须为各个应用场景预留,这样的内存称之为预留内存;
- 内存其余的部分,是需要内核管理的内存,称之为动态内存。
那么memblock就是将以上内存按功能划分为若干内存区,使用不同的类型存放在memory和reserved的两个集合中,memory即为动态内存,而resvered包括静态内存等。
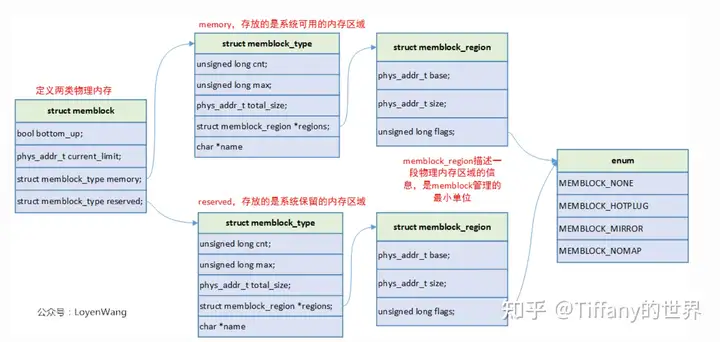
memblock的算法实现是,它将所有的状态都保持在一个全局变量__initdata_memblock中,算法的初始化以及内存的申请释放都是在将内存块的状态做变更。那么从数据结构入手,__initdata_memblock是一个memblock结构体,其定义如下:
struct memblock {
bool bottom_up; /* is bottom up direction? */
phys_addr_t current_limit;
struct memblock_type memory;
struct memblock_type reserved;
#ifdef CONFIG_HAVE_MEMBLOCK_PHYS_MAP
struct memblock_type physmem;
#endif
};这个结构体包含五个域。
- 第一个 bottom_up 域置为 true 时允许内存以自底向上模式进行分配。
- 下一个域是 current_limit 这个域描述了内存块的尺寸限制。
- 接下来的三个域描述了内存块的类型。内存块的类型可以是:被保留内存和物理内存(如果 CONFIG_HAVE_MEMBLOCK_PHYS_MAP 编译配置选项被开启)。
memory和reserved是很关键的一个数据结构,memblock算法的内存初始化和申请释放都是围绕着他们展开工作。往下看看memory和reserved的结构体memblock_type定义:
struct memblock_type {
unsigned long cnt; /* number of regions */
unsigned long max; /* size of the allocated array */
phys_addr_t total_size; /* size of all regions */
struct memblock_region *regions;
};这个结构体提供了关于内存类型的信息。它包含了描述当前内存块中内存区域的数量、所有内存区域的大小、内存区域的已分配数组的尺寸和指向 memblock_region 结构体数据的指针的域。
struct memblock_region {
phys_addr_t base;
phys_addr_t size;
unsigned long flags;
#ifdef CONFIG_HAVE_MEMBLOCK_NODE_MAP
int nid;
#endif
};memblock_region 提供了内存区域的基址和大小,flags 域可以是:
#define MEMBLOCK_ALLOC_ANYWHERE (~(phys_addr_t)0)
#define MEMBLOCK_ALLOC_ACCESSIBLE 0
#define MEMBLOCK_HOTPLUG 0x1这三个结构体: memblock, memblock_type 和 memblock_region 是 Memblock 的主要组成部分。
memblock api
memblock子模块,基本的逻辑都是围绕内存的添加和移除操作来展开。
int memblock_add(phys_addr_t base, phys_addr_t size);
int memblock_remove(phys_addr_t base, phys_addr_t size);最终是通过调用memblock_add_range/memblock_remove_range来实现的。
static int __init_memblock memblock_add_range(struct memblock_type *type,
phys_addr_t base, phys_addr_t size,
int nid, enum memblock_flags flags)
static int __init_memblock memblock_remove_range(struct memblock_type *type,
phys_addr_t base, phys_addr_t size)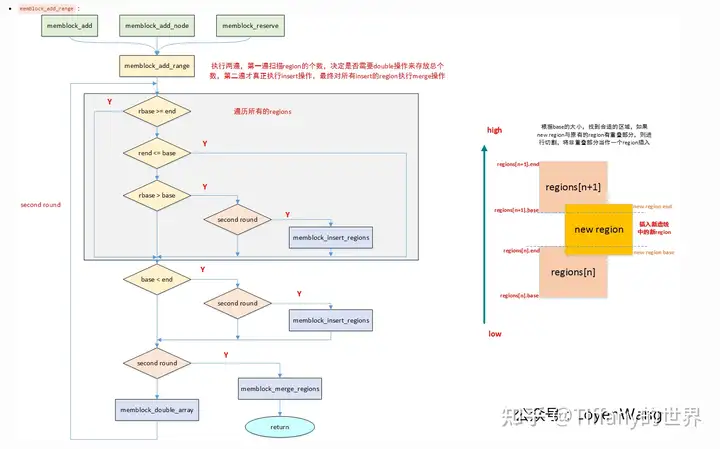
memblock添加保留内存
这种方式主要是在内存的reserved-memory节点中添加保留内存,示例:
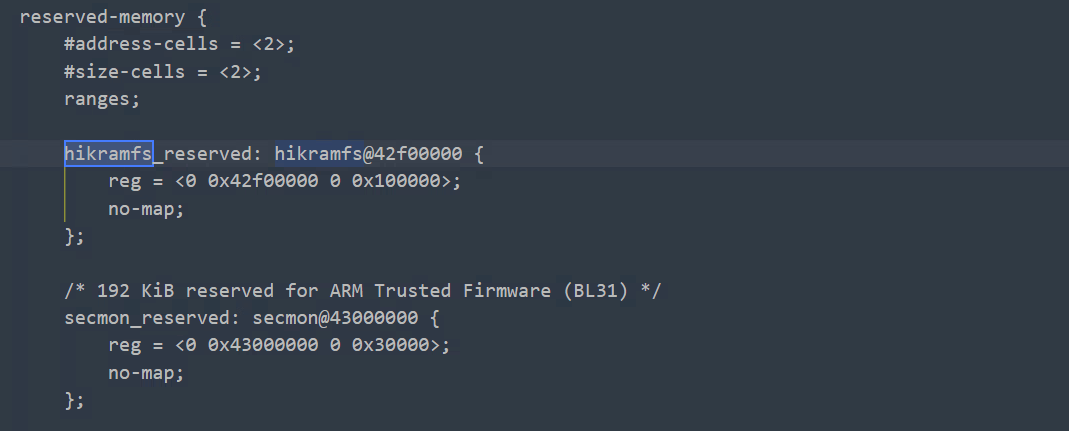
使用这种方式基本原理是基于内核memblock,流程如下:
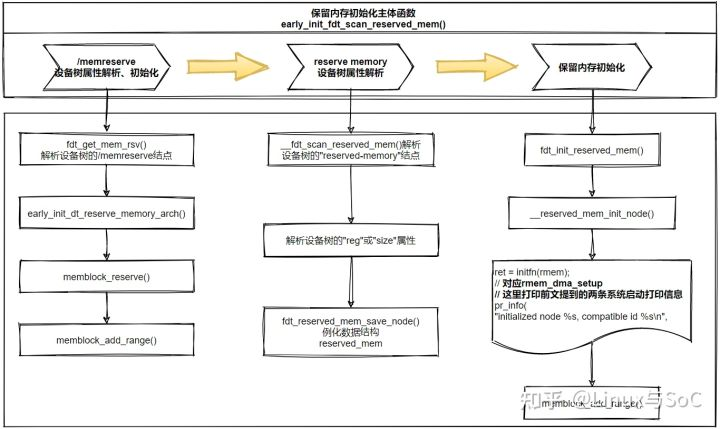
最终就是通过调用memblock_add_range注册保留内存。
当然对于没有设备树的平台也可以通过这个接口进行注册:
diff -uNrp a/arch/x86/kernel/setup.c b/arch/x86/kernel/setup.c
--- a/arch/x86/kernel/setup.c 2021-01-29 23:09:08.443072526 -0800
+++ b/arch/x86/kernel/setup.c 2021-01-29 23:31:53.521307672 -0800
@@ -907,6 +907,8 @@ static void rh_check_supported(void)
void __init setup_arch(char **cmdline_p)
{
+
+ struct memblock_region *reg;
memblock_reserve(__pa_symbol(_text),
(unsigned long)__bss_stop - (unsigned long)_text);
@@ -1035,6 +1037,13 @@ void __init setup_arch(char **cmdline_p)
* again from within noexec_setup() during parsing early parameters
* to honor the respective command line option.
*/
+
+ memblock_reserve(0x100000000, 0x2000000);
+ pr_info("Scan equal region:n");
+ for_each_memblock(reserved, reg) //遍历打印reserved所有分区
+ pr_info("Region [%llx -- %llx]n", (u64)(reg->base),
+ (u64)(reg->base + reg->size));
+
x86_configure_nx();
parse_early_param();使用这种方式的内存分布如下:
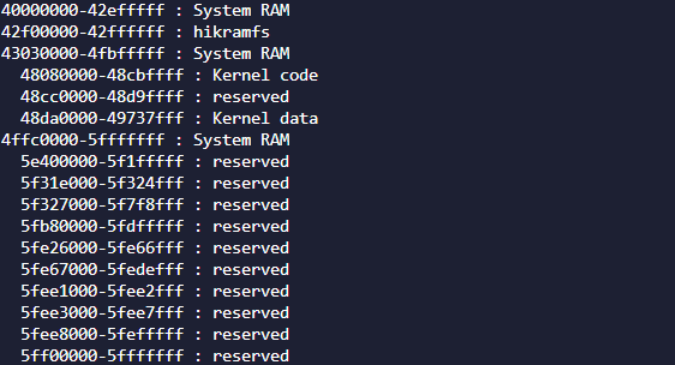
需要注意的这块内存的位置是有讲究的,不是每一块物理内存都可以存放,需要了解uboot与内核的内存使用情况,一般来说在这种不能使用最后的内存,因为uboot的重定位会使用到内存的高地址,也不能使用最开始的内存,有的平台可能Uboot会直接加载在内存开始位置,重启后这些内存会被uboot破坏掉。
这种方式的有点是改动很小,对于有设备树的平台只需要添加节点即可,但是也有缺点就是会造成物理内存被分成两段,还有就是对于无设备树的平台也需要修改内核代码注册memblock。
预留内存使用
讲明白怎样创建预留内存,那么怎么使用预留内存呢。
static char data[] = "123456n";
static void* addr;
static int __init ram_reserve_init(void)
{
if (!request_mem_region(0x40000000, 0x20000000, "reserve test")) //请求不可见的内存段权限(即:检查你申请的资源是否可用,如果可用,则将其标志为被使用。非必须)
{
printk("request_mem_region failn");
return - EBUSY;
}
addr = ioremap(0x40000000, 0x20000000, MEMREMAP_WB); //映射内存空间
memcpy(addr, data, sizeof(str)); //拷贝测试数据
printk( "%s: %sn " , __func__, ( char * )addr);//读出内存数据
return 0;
}
static void __exit ram_reserve_exit(void)
{
iounmap(addr);
release_mem_region(RESERVE_PHY, RESERVE_SIZE);
pr_info(KBUILD_MODNAME ": unloaded.n");
}
module_init(ram_reserve_init);
module_exit(ram_reserve_exit);
request_mem_region() 检查你申请的资源是否可用,如果可用,则将其标志为被使用,如果该内存区已经被标记,会返回报错,该调用可以忽略,建议加上。
对于物理内存可以使用memremap或者ioremap将其映射到虚拟内存空间上,也就是vmalloc区的某段虚拟内存映射到io memory。与 vmalloc() 不同的是,ioremap() 并不需要通过伙伴系统去分配物理页。memremap本身也是ioremap的变体,两者主要区别就在于ioremap默认是禁用cpu cache的,而memremap则默认允许读写缓存。

留言